The AI Interconnect Layer: Where GPU, ASIC, and CPU Meet AI Photonics — and Where Most Investors Haven't Looked
Compute is just the beginning. The interconnect layer downstream of GPUs and ASICs is where the next $50B+ of AI capex flows — Swedish retail investors are barely tracking the names that matter.


"Follow the money." It's the most useful piece of investigative advice ever offered, and it works just as well for AI infrastructure as it did for political reporting.
It's old advice, but it works. In the previous post, The AI Compute Stack, we mapped Goldman's 5 years $7.6T AI capex framework, and how that connects to GPUs, custom ASICs, and CPUs (first part of this series: read more here). Today the compute layer, is the most visible, most discussed, and most understood part of the stack.
But compute is where the AI infrastructure money story starts. Not where it ends.
Compute is just the beginning. Once you've assembled 100,000 GPUs in a hyperscaler campus, you have a fundamentally new problem: connecting them. The interconnect layer downstream of compute is where AI infrastructure becomes physically real, and it's where the next architectural battle is being fought.
This is also where Swedish investor attention falls off a cliff. To illustrate this let’s take a look at Avanza, Sweden's largest retail trading platform. NVIDIA: ~98,000 Swedish shareholders. AMD: ~28,000. These are widely held names. Then drop one layer downstream into custom ASICs and networking: Broadcom ~10,000 holders. Marvell ~2,000. And drop one more layer into the optical interconnect names that actually capture the dollar flow when AI clusters scale: Lumentum ~800 holders. Coherent ~800 holders.
The discovery curve is steep. Most retail investors stop tracking at the brand-name compute layer. The interconnect layer, where the bandwidth, the power efficiency, and arguably the larger long-term economics live, remains mostly invisible to non-specialists.
That's an opportunity!
Why Compute Without Interconnect Is Useless
A 100,000-GPU cluster is just 100,000 islands of computation if you can't move data between them. AI training workloads are bandwidth-bound long before they're compute-bound. The economics flow accordingly.
Three constraints make optical interconnect non-optional at AI cluster scale.
Bandwidth density. Each generation of AI accelerator demands roughly 2x interconnect bandwidth. NVIDIA's NVLink 5 in Blackwell delivers 1.8 TB/s per GPU. The next generation targets 3.6 TB/s. Copper traces at these speeds become unmanageable in PCB routing within just a few inches.
Power per bit. At 200 Gbps per lane, electrical SerDes consume approximately 5 picojoules per bit. Optical equivalents target 1 pJ/bit. Across a 100,000-GPU cluster running continuously, the aggregate power difference reaches hundreds of megawatts — which is why hyperscaler power budgets increasingly drive networking architecture decisions.
Distance. Copper performance degrades sharply beyond ~1 meter at AI cluster speeds. Optical maintains signal integrity across racks, rows, and entire data center halls without amplification.
The optical transition isn't optional. It's an engineering inevitability for AI clusters scaling toward 100,000+ GPU deployments. The contested questions are when each architectural layer transitions, who wins each transition, and what counts as the addressable market.
Two Markets, Not One
The first thing to understand about optical interconnect is that the analyst forecasts disagree by a factor of 65. Mordor Intelligence sees a $2 billion CPO market by 2030. DigiTimes projects $130 billion. That's not methodological imprecision. It's that "CPO market" actually means two distinct architectures with different economics, different vendors, and different timing.

Coherent investors presentation OFC
Scale-out optics — rack-to-rack networking. Already a mature market dominated by pluggable transceivers. This is where 800G and 1.6T pluggables live, where Coherent and Lumentum compete with Innolight and Hisense, and where Broadcom's Tomahawk switch ASICs are increasingly winning silicon-photonics integration deals.
Scale-up optics — chip-to-chip within a rack. The contested frontier. This is where Ayar Labs, Marvell's Photonic Fabric (post-Celestial AI acquisition), POET Technologies' Optical Interposer, and external light source vendors like Lumentum, Coherent, Sivers Semiconductors compete for what could become a fundamentally larger market by 2030.
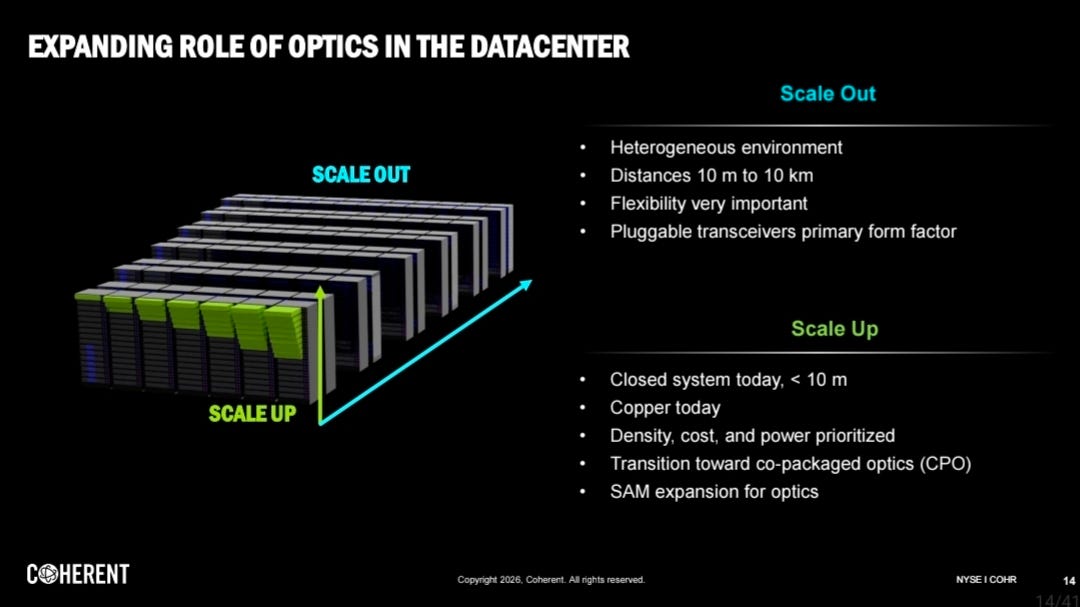
These two markets share underlying physics, both move bits via photons rather than electrons — but the economics, the vendor landscape, and the deployment timing are genuinely different. Most retail and even institutional commentary conflates the two.
The Scale-Out Story: Pluggables and Switch ASICs
Scale-out optics is the more mature market, and the more concentrated. Three players matter most.
Coherent Inc. is the merchant pluggable transceiver leader. Their Q1 2026 earnings disclosed total optical SAM of $50 billion in their existing markets, with $20 billion incremental SAM from emerging AI applications by 2030. That $70 billion total SAM by 2030 is a useful anchor for evaluating other forecasts.
Coherent's strategic position is strong because they have InP fabrication capability (acquired through II-VI). InP wafer supply is a structural bottleneck for AI optics, and Coherent controls a meaningful share of merchant InP capacity.
Lumentum is Coherent's primary competitor in pluggables. Lumentum has historically been stronger in DSP-based pluggables and has deep relationships with NVIDIA on indium phosphide laser supply for both pluggable and emerging CPO applications.
Broadcom sits at a different layer but increasingly captures pluggable economics through their switch ASICs. The Tomahawk 5-Bailly platform integrates silicon photonics directly into the switch, displacing pluggable transceivers in some hyperscaler deployments. Broadcom shipped 50,000+ Bailly units in 2025 and is ramping capacity for 2026 deployments at Google, Microsoft, and Meta.
Three drivers worth tracking:
800G and 1.6T pluggables ramp. LightCounting projects pluggables retain 80%+ market share through 2030, even as CPO grows.
LPO/LRO emergence. Power-optimized pluggable variant that competes with CPO at the rack level. AOI, Jabil and Hisense are leading here.
LPO (Linear Pluggable Optics): Removes the Digital Signal Processor (DSP) entirely from the transceiver, relying on the switch ASIC for signal equalization. This offers the lowest power but has higher interoperability risks.
LRO (Linear Receive Optics): Also known as "Half Retimed Optics," it keeps a DSP on the transmitter side (for signal stabilization) while removing it from the receiver side. It offers roughly half the power savings of LPO, but with superior link stability and easier adoption. (Jabil latest solution under development).
Tomahawk-style switch ASIC integration. Broadcom's silicon photonics integration displaces some merchant pluggable revenue but creates new architectural dependencies on Broadcom-designed clusters.
Scale-out is real, growing, and increasingly dominated by the Broadcom-Coherent-Lumentum triangle.
The Scale-Up Story: Where the Real New Money Could Be!
Scale-up optics is the new frontier and the larger long-term opportunity.
The architectural premise: as accelerator clusters scale, the bottleneck shifts from rack-to-rack bandwidth (where pluggables work fine) to chip-to-chip bandwidth within the rack. Once you need 10+ TB/s of bandwidth between accelerators in a single chassis, copper electrical interconnect becomes physically impossible. Optical chip-to-chip is the only path forward.
Several vendors are competing for this scale-up layer.
Ayar Labs has shipped TeraPHY optical I/O chiplets and SuperNova external light sources. They're funded by Intel, NVIDIA, and the US Department of Defense, with deployments at AWS Trainium and Intel's accelerator programs. Ayar Labs' architecture co-packages an optical I/O chiplet directly with the accelerator die, with light sources provided externally for thermal isolation.
Marvell acquired Celestial AI for $3.25 billion in December 2025. Celestial AI's Photonic Fabric technology is direct competition with Ayar Labs in the chip-to-chip optical layer. The acquisition gives Marvell a complete custom ASIC + optical interconnect platform, a structural advantage versus Broadcom, which would need to build optical interconnect capability separately.
POET Technologies offers the Optical Interposer platform, a different architectural approach that integrates lasers, modulators, photodetectors, and CMOS electronics on a single substrate.
NVIDIA's Spectrum-X and Quantum-X CPO switches were announced for 2026 deployment. NVIDIA's approach integrates silicon photonics directly into their networking ASICs, similar to Broadcom's Bailly platform but for AI clusters specifically.
External Light Sources (ELS), the laser layer, is a separate but adjacent market. Most scale-up optical architectures use externally located lasers (rather than integrating laser sources directly with the accelerator) for thermal management reasons. This creates a market for high-power, narrow-linewidth InP lasers from vendors including Lumentum, Coherent, MACOM, Sivers Semiconductors etc.
The scale-up market is more contested, less mature, and harder to size. But it's where the larger long-term economics could land if hyperscalers genuinely transition to optical chip-to-chip at the volumes some analysts project (which the market now believes will happen).
The Sizing Disagreement Decoded
Now the analyst forecast spread makes sense.
Optimistic forecasts ($50-130B by 2030):
DigiTimes: 142% CAGR (excluding ELS)
Yole Group: $8.1B by 2030, 137% CAGR
Coherent's own SAM: $70B + total by 2030
These forecasts include scale-up optics, ELS, and the implicit assumption that chip-to-chip optical reaches significant deployment by 2030.
Conservative forecasts ($2-8B by 2030):
Mordor Intelligence: 36% CAGR
IDTechEx: 37% CAGR
These forecasts focus narrowly on "true CPO", defined as silicon photonics modules co-packaged with switch or accelerator ASICs. They exclude pluggables, exclude ELS, and apply more conservative assumptions about scale-up adoption timing.
Both lenses are correct. They're measuring different things. The 65x spread reflects definitional differences, not analytical error.
What Avanza Numbers Actually Tell Us
Back to the Swedish retail discovery curve.
NVIDIA's ~98,000 Swedish shareholders on Avanza reflect what works at the brand layer: a name everyone has heard of, a stock everyone has read about, a chart everyone has watched go vertical. AMD's ~28,000 holders reflect the second-mover effect, the credible challenger, recognizable enough to be a "second AI bet."
Then the layered drop. Broadcom's ~10,000 Swedish holders is interesting because Broadcom genuinely is one of the largest AI infrastructure beneficiaries, by some measures more than AMD. Broadcom captures roughly 60-70% of the custom ASIC market (anchored by Google TPU and Meta MTIA), runs the dominant networking switch ASIC franchise (Tomahawk 5-Bailly with 50,000+ units shipped in 2025), and is increasingly capturing pluggable transceiver economics through silicon photonics integration. Yet its Swedish retail holder base is roughly one-third of AMD's, despite arguably broader AI exposure.
Then another step down. Marvell at ~2,000 holders reflects the gap between merchant GPU recognition and custom ASIC understanding. Marvell is the second major custom ASIC design house, anchored by AWS Trainium and Microsoft Maia programs. Its custom silicon business runs at $1.5 billion annualized revenue, and its December 2025 acquisition of Celestial AI for $3.25 billion gave it integrated optical interconnect capability. By any analytical measure, Marvell is more central to the AI infrastructure story than its Swedish retail visibility suggests.
Lumentum at ~800 holders. Coherent at ~800 holders. These are the merchant pluggable leaders directly capturing optical interconnect dollars as AI clusters scale. The combined Avanza holder count for Lumentum and Coherent (~1,600) is 5% of AMD's Swedish retail base — and 1.6% of NVIDIA's.
The discovery curve compresses dramatically as you move downstream:
NVIDIA: ~98,000 holders (compute, brand layer)
AMD: ~28,000 (compute, second source)
Broadcom: ~10,000 (custom ASIC + networking)
Marvell: ~2,000 (custom ASIC second mover)
Lumentum: ~800 (optical interconnect)
Coherent: ~800 (optical interconnect)
The gap matters because it tells you something about market efficiency. Brand-layer compute names trade on broad investor attention. Interconnect-layer names trade on a much narrower base of specialists. That's not necessarily mispricing, sometimes the broader investor base is right and the specialists are over-confident. But it's a structural feature worth knowing about.
Worth noting is the share price development over the last year
AI Photonics layer: Lumentum +1200% , Coherent +400%
Upstream: Broadcom +100%, Marvell 200%, NVIDIA +80%, AMD 350%.
The later group for example NVIDIA have had an early revaluation over 3 years at +600%.
For a Swedish investor specifically: the discovery curve from NVIDIA → Lumentum is a 99% reduction in retail competition.
What This Means for Vendor Selection
The architectural split clarifies vendor strategy.
For scale-out exposure (more concentrated, more mature):
Coherent — InP capability + pluggable leadership
Lumentum — DSP pluggables, NVIDIA relationships
Broadcom — switch ASIC integration capturing pluggable economics
AOI, Innolight — pluggable competition
For scale-up exposure (more contested, more upside):
Ayar Labs — direct chip-to-chip optical I/O
Marvell (Celestial AI) — integrated ASIC + optical platform
POET Technologies — Optical Interposer architecture
NVIDIA — Spectrum-X/Quantum-X CPO switches
Laser/ELS/Materials suppliers: Lumentum, Coherent, MACOM, Sivers, AXT, IQE.
An AI bet on Macro level with a diversified portfolio across all layers captures the architectural transition without taking a position on which scale-up architecture wins, also including Hyperscalers could be even better. A concentrated bet on scale-up specifically requires a higher-conviction but gives a higher-variance.
Hence Macro plays in all layers in the stack could be a possible path, including: Hyperscaler - GPU/CPU - ASIC - AI Photonics - Lasers - Materials (to simplify the stack).
What to Watch in 2026-2027
Several deployment data points will resolve much of the architectural uncertainty over the next 24 months:
1. NVIDIA Spectrum-X / Quantum-X production deployments. Confirmed for 2026 but with limited disclosed deployment scale. AMD 2026 data on CPU to GPU ratio change.
2. Marvell Photonic Fabric customer disclosures. Post-Celestial AI integration, Marvell needs to disclose hyperscaler design wins for the integrated ASIC + optical platform. Without disclosed wins by H2 2026, the $3.25B acquisition thesis weakens.
3. Ayar Labs production scale. Ayar Labs has shipped engineering samples but commercial deployment scale remains unclear. Production ramps in 2026 would validate the chip-to-chip optical architecture broadly.
4. Broadcom Bailly volume trajectory. Broadcom shipped 50,000+ units in 2025. The 2026 trajectory determines whether silicon photonics integration in switch ASICs becomes the dominant scale-out architecture or remains a niche optimization.
5. InP lasers and wafer supply expansion. Multiple vendors (Lumentum, Coherent, MACOM, Sivers, AXT, IQE) are expanding InP capacity. The pace of capacity addition relative to demand growth determines whether laser supply becomes a structural bottleneck.

The Architectural Takeaway
Optical interconnect isn't one market. It's two markets with shared physics but distinct economics.
Scale-out optics is real, growing, and concentrating around Broadcom-Coherent-Lumentum. The economics are good but the structural growth is moderate for the incumbents, but could be huge for new players.
Scale-up optics is contested, still less mature, and harder to size. But it's where the larger long-term economic opportunity lives if hyperscalers genuinely transition to optical chip-to-chip at the volumes some analysts project.
The dollar flow inside Goldman's networking line item depends critically on which scale-up architecture wins, when it wins, and at what deployment volume. Analyst spreads of 65x reflect that genuine uncertainty — not analytical sloppiness.
The vendors building credibly in scale-up, Ayar Labs, Marvell post-Celestial AI, POET, NVIDIA's CPO switches, and the external light source ecosystem, are competing for what could be the most valuable layer of the AI infrastructure stack.
Watch the deployment data over 2026-2027. The architectural question resolves in the actual chips that ship, not in the analyst forecasts. And while the broad retail attention concentrates on the brand-layer compute names, the interconnect layer is quietly capturing an increasing share of the actual AI capex dollars.
Anders Storm
Disclosure: I am a shareholder in AMD, Marvell and Sivers and the former CEO of Sivers Semiconductors (2017-2024). This commentary reflects publicly available information and the author's analytical framework. Nothing in this post constitutes investment advice or a recommendation to buy or sell any security. Avanza shareholder figures are approximate retail holdings on the Swedish trading platform Avanza Bank.
Genuinely one of the clearest breakdowns of the interconnect layer I've come across. The InP supply bottleneck you flagged is interesting — do you see indium supply concentration creating a geopolitical dependency similar to what we're watching play out in rare earths and other critical minerals? Curious whether that's on the radar of the vendors expanding capacity.